
A lot of information on the internet is burried under html instead of neatly formatted Json.
As an example of how to scrape these complex htmls, we will try to answer: Give me the list of ETFs traded in India sorted by expense ratio
Scrape Strategy 1: FindAll and Pattern Match
Here's a list of ETFs from MoneyControl
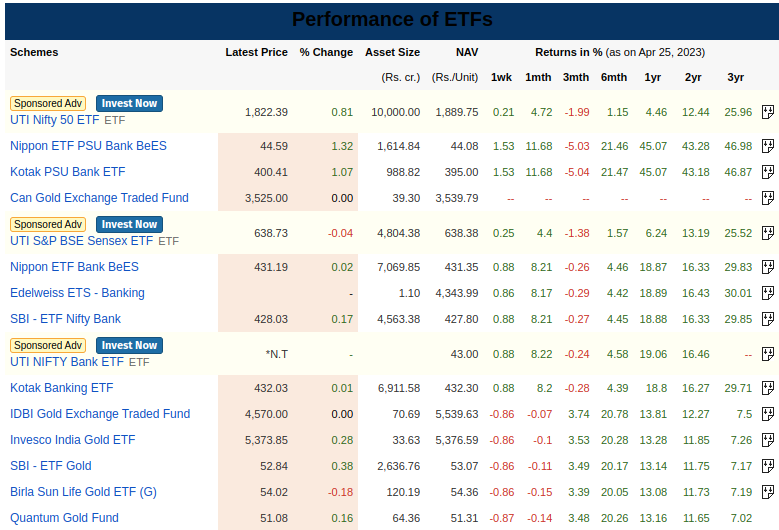
The html that renders this table is a deeply nested object.
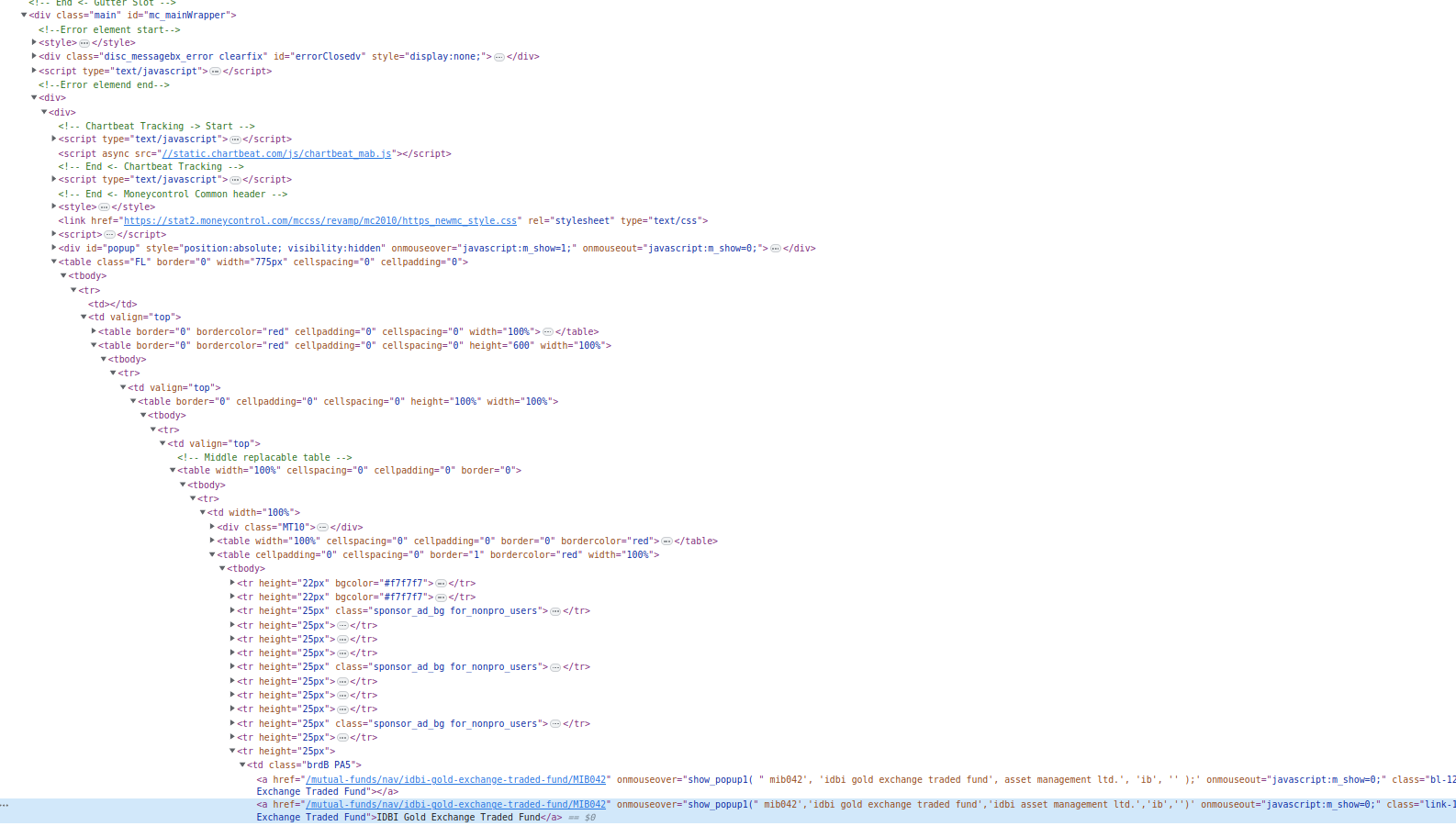 Good thing is the object of interest(ETF) is an anchor tag
Good thing is the object of interest(ETF) is an anchor tag <a> all having the same prefix in href
<a
href="https://www.moneycontrol.com/mutual-funds/nav/idbi-gold-exchange-traded-fund/MIB042"
>IDBI Gold Exchange Traded Fund</a
>
<a
href="https://www.moneycontrol.com/mutual-funds/nav/uti-nifty-exchange-traded-fund/MUT2096"
>UTI Nifty 50 ETFETF</a
>
...
Using Puppeteer we can fetch all the anchor elements in the page and filter out the ones whoese href start with https://www.moneycontrol.com/mutual-funds/nav/
Modern websites take a while to load all the dom elements as there is javascript involved which fetches dynamic ajax contents. We need to wait a bit before the page is fully loaded. For this we use page.waitForSelector(). This selector will vary based on the site/url we are rending - we have to lookout for any element or in this case an element with a specific class that can guarantee that once it is available our element of concern are also available.
In most cases if the element of concern has a unique property then it's better to have it as the selector. Here the ETF table has a unique class EF that we will be waiting on. As this is a class we will be using .EF where . signifies class selector
import puppeteer from "puppeteer";
import { promises as fs } from "fs";
const createListOfAnchors = async (browser) => {
const browser = await puppeteer.launch({ headless: "new" });
const page = await browser.newPage();
// Goto url
await page.goto("https://www.moneycontrol.com/mf/etf/");
// Wait for the table to populate
await page.waitForSelector(".FL");
// Fetch all anchor<a href="..."> Link </a> tags
let anchors = await page.$$eval("a", (as) => {
return as.map((a) => ({ title: a.textContent, href: a.href }));
});
// Weed out anchors that do not have prefix
anchors = anchors.filter(
(a) =>
a.title !== "" &&
a.href.startsWith("https://www.moneycontrol.com/mutual-funds/nav")
);
// Write to console and .json file
console.table(anchors);
fs.writeFile("moneycontrol.json", JSON.stringify(anchors, null, 4), (err) =>
console.log(err ? err : "JSON saved to " + "moneycontrol.json")
);
browser?.close();
return anchors;
};
The above function will dump a list of ETF names and there URL's:
| Title | Href |
|---|---|
| UTI Nifty 50 ETFETF | https://www.moneycontrol.com/mutual-funds/nav/uti-nifty-exchange-traded-fund/MUT2096 |
| Nippon ETF PSU Bank BeES | https://www.moneycontrol.com/mutual-funds/nav/nippon-india-etf-psu-bank-bees/MBM018 |
| Kotak PSU Bank ETF | https://www.moneycontrol.com/mutual-funds/nav/kotak-psu-bank-etf/MKM178 |
| Nippon ETF Bank BeES | https://www.moneycontrol.com/mutual-funds/nav/nippon-india-etf-bank-bees/MBM004 |
| UTI S&P BSE Sensex ETFETF | https://www.moneycontrol.com/mutual-funds/nav/uti-sensex-exchange-traded-fund/MUT2098 |
| ... | ... |
Scrape Strategy 2: Chrome devtools for Selector Query
Each ETF link takes us to a page that has the expense ratio:
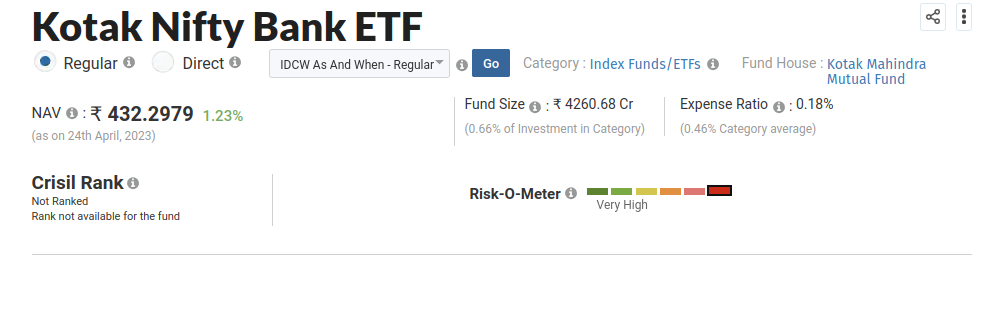
Using the Cursor Select tool in Chrome's Dev tool we can directly jump the the element that renders Expense Ratio
From there we can grab the selector by Right Click Element -> Copy -> Copy Selector
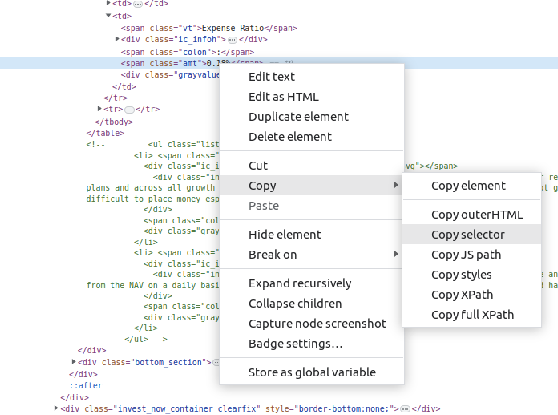
We can directly use this selector to grap the expense ratio:
const sequentialScrapeEtf = async (browser, anchors) => {
const failed = [];
for (let anchor of anchors) {
try {
const page = await browser.newPage();
await page.goto(anchor.href);
const navDetailsSelector = ".navdetails";
await page.waitForSelector(navDetailsSelector);
// Use Chrome dev tools -> Element -> Right Click -> Copy -> Copy Selector
const sel =
"#mc_content > div > section.clearfix.section_one > div > div.common_left > div:nth-child(3) > div.right_section > div.top_section > table > tbody > tr:nth-child(1) > td:nth-child(2) > span.amt";
const el = await page.waitForSelector(sel);
const text = await el.evaluate((el) => el.textContent.trim());
// Remove the % sign at the end and convert it String to Float
anchor["expenseRatio"] = parseFloat(text.replace("%", ""));
console.log(`Resolved ${anchor["href"]}: ${anchor["expenseRatio"]}`);
await page.close();
} catch (err) {
console.log(`Failed for ${anchor["title"]}`, err);
failed.push(anchor["title"]);
}
}
console.log("Failed for", failed.length, "items");
};
Et Voila! This returns our table of expense ratios:
ETF with the name Invest Now and expense ratio with null/undefined are a result of ads and broken links. I left it out to show that things still might fail and we need to have some filtering logic to remove these entries
Putting all together
The source can be found in github.
Improvements
I am fetching ETF's expense ratio sequentially which is too damn slow and downright not practical. A parallel strategy should be utilized to fetch the pages.